
The Story (skip if ya just want the code)
I’ve fussed with this problem for weeks. If you need to import massive amounts of csv data (100k to 10mil) to your Laravel site there’s a lot of broken information. Some of it is outdated, others are just bits and pieces. But here’s generally how the story goes.
- Find a library (Laravel Excel, Fast Excel)
- Find out that these don’t exactly match your specs (either)
- Hits memory limits (no batch/chunk support)
- Doesn’t support s3 storage down streams
- Too slow
- Get frustrated
Laravel Excel is a feature-rich library and has a lot of support but is not fast enough for more than 100k rows. Fast Excel is fast! But doesn’t have the features.
For example, in Laravel Excel, inserting 500k rows took around 8 hours with Heroku’s Standard 1X dyno (512MB RAM and 1x CPU share). Which is too long for business use. Fast Excel claims it has about 5% of Laravel Excel’s memory usage and a fifth of the execution time but those benchmarks are for exports and I can’t use it with an online storage stream with chunk/batch inserts (as far as I know).
So the only conclusion was to write my own. Fast excel is a wrapper around PhpSpreadsheet, and Fast Excel uses Sprout. But it feels like too much work to write a wrapper of my own or create a fork just for one function.
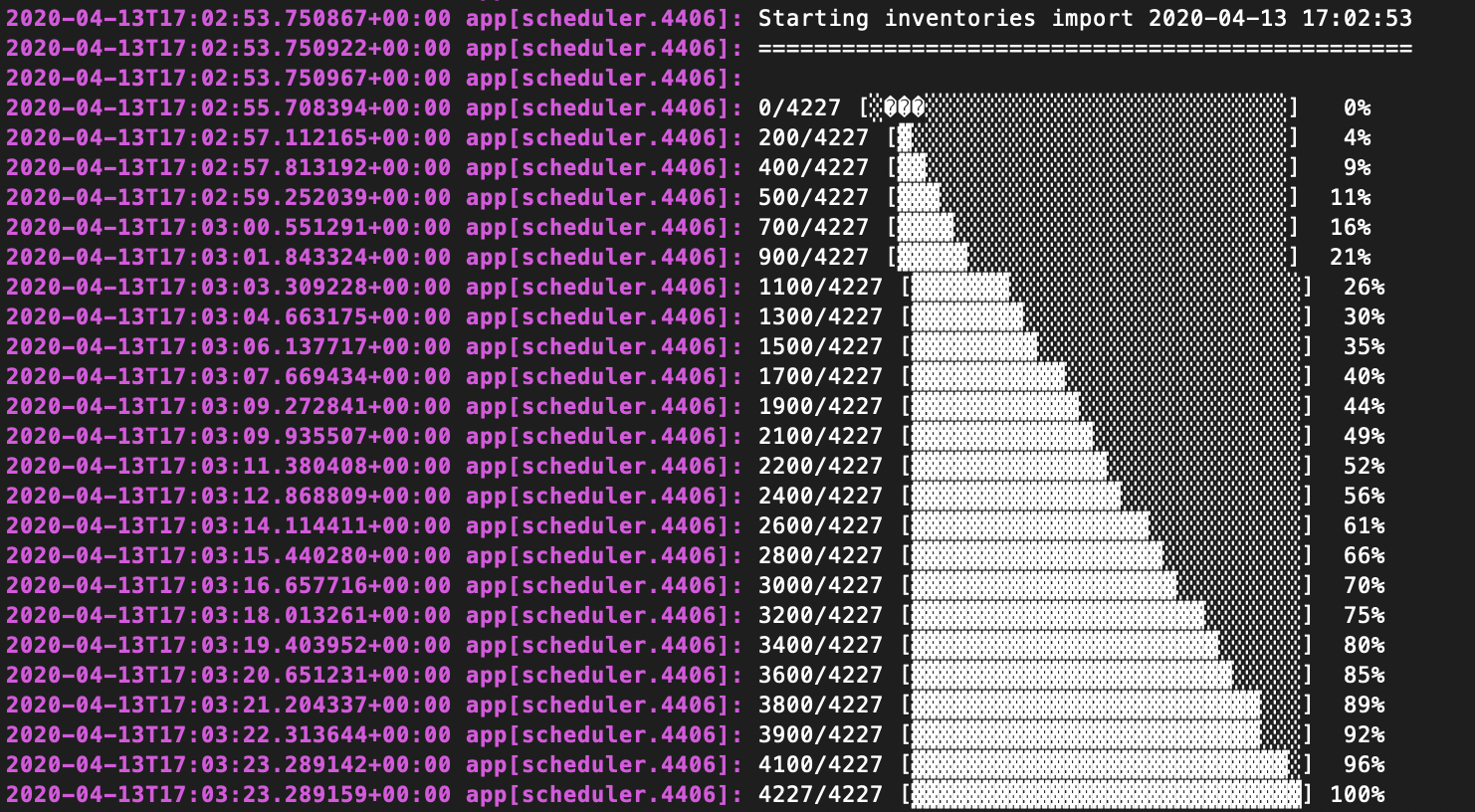
So, here’s how I got an 8 hour Laravel csv import job down to 8 minutes using a few lines of code instead of a library.
Streaming from S3
This part is pretty simple and well explained in the docs. I’m going to skip configuring S3 with Laravel here since that info is pretty easy to find.
$sourcePath = 'csvFolder/your.csv';
$stream = Storage::disk('s3')->getDriver()->readStream($sourcePath);Reading a stream is fast! Almost instantaneous. So the bottleneck is probably the inserts.
Read the data
This part is a little more complicated. I opted to use php native fgetcsv() function.
- Prep the data
- fgetcsv()
- Get rows in batches
- Parse header row
- Handle BOM <- pain in the ass
I used the following resources
- CSV importer class using fgetcsv()
- Forgot where I got how to handle BOM
TL;DR of Byte Order Mark
BOM is an invisible set of bytes (usually three) at the beginning of the file that tells the program it’s unicode encoded and will mess with your system. You need to compare the first three bytes to bom signatures to make sure the file contains it before removing them.
Create and use the following importer class.
class CsvImporter
{
private $fp;
private $parse_header;
private $header;
private $delimiter;
private $length;
function __construct($stream, $parse_header=false, $delimiter=",", $length=8000)
{
$this->fp = $stream;
$this->parse_header = $parse_header;
$this->delimiter = $delimiter;
$this->length = $length;
if ($this->parse_header)
{
$this->header = fgetcsv($this->fp, $this->length, $this->delimiter);
}
}
function __destruct()
{
if ($this->fp)
{
fclose($this->fp);
}
}
function get($max_lines=0)
{
//if $max_lines is set to 0, then get all the data
$data = array();
if ($max_lines > 0)
$line_count = 0;
else
$line_count = -1; // so loop limit is ignored
while ($line_count < $max_lines && ($row = fgetcsv($this->fp, $this->length, $this->delimiter)) !== FALSE)
{
if ($this->parse_header)
{
foreach ($this->header as $i => $heading_i)
{
//handle bom?
$bom = pack("CCC", 0xef, 0xbb, 0xbf);
if (0 == strncmp($heading_i, $bom, 3)) {
$heading_i = substr($heading_i, 3);
}
//transpose
$row_new[$heading_i] = $row[$i];
}
$data[] = $row_new;
}
else
{
$data[] = $row;
}
if ($max_lines > 0)
$line_count++;
}
return $data;
}
}
Insert
Handle the data:
- Validate
- Pack the array
- Insert
This thread on Laracasts from @alex_storm was very insightful on insert benchmarks and different methods.
// 23400 records/min
// one at a time
foreach ($records as $record)
{
DB::table($table)->insert($record);
}
// 40 records/min.
// 50000 at a time or regardless of amount
DB::table($table)->insert([$records]);
// 230000 records/min
// 50000 at a time
// generate data for the insert
DB::insert('INSERT INTO '.$prefix.$table.' ('.$columns.') VALUES '.$values);To balance speed and memory usage, I use a foreach loop in the following example.
Call
Depending on which method you use and how many you insert at a time, you’ll hit different speeds and memory limits. Using option #2 and the CsvImporter class we made, here’s the use case.
use CsvImporter;
DB::disableQueryLog(); // saves memory and speed
$source = 'csvFolder/your.csv';
$stream = Storage::disk('s3')->getDriver()->readStream($source);
$importer = new CsvImporter($stream,true);
$batch = 50; //best for my local machine try 1 to 1k
while($data = $importer->get($batch))
{
$validated = [];
foreach($data as $row){
// validate row
$validated[] = [
'Date' => Carbon::parse($row['Date']),
'Status' => $row['Status'] ?: 'default',
];
}
//insert
DB::table('sales')->insert($validated);
}Conclusion
I was able to get 500k rows in about 8 minutes without hitting 1GB of memory. Much faster than 8 hours!
*Laravel 6.2